At the recent AAAS meeting Dr Genevera Allen gave a talk in which she highlights a rather interesting problem that specifically relates to the use of machine learning.
Sitting between our ears is a pattern seeking engine that can and will at times identify false positives. We build in our own image and so we live in an age where we can now utilise machine learning to scan very large datasets looking for patterns.
Here is the press release that specifically relates to her AAAS talk …
Can we trust scientific discoveries made using machine learning?
The short quick answer is “no, you must verify it”.
The problem is that once you identify a pattern it can be very tempting to rush to publish without proper verification or even appreciating that you have simply fooled yourself.
She explains …
… “The question is, ‘Can we really trust the discoveries that are currently being made using machine-learning techniques applied to large data sets?'” Allen said. “The answer in many situations is probably, ‘Not without checking,’ but work is underway on next-generation machine-learning systems that will assess the uncertainty and reproducibility of their predictions.”…
…”A lot of these techniques are designed to always make a prediction,” she said. “They never come back with ‘I don’t know,’ or ‘I didn’t discover anything,’ because they aren’t made to.”
She said uncorroborated data-driven discoveries from recently published ML studies of cancer data are a good example.
“In precision medicine, it’s important to find groups of patients that have genomically similar profiles so you can develop drug therapies that are targeted to the specific genome for their disease,” Allen said. “People have applied machine learning to genomic data from clinical cohorts to find groups, or clusters, of patients with similar genomic profiles.
“But there are cases where discoveries aren’t reproducible; the clusters discovered in one study are completely different than the clusters found in another,” she said. “Why? Because most machine-learning techniques today always say, ‘I found a group.’ Sometimes, it would be far more useful if they said, ‘I think some of these are really grouped together, but I’m uncertain about these others.'”
What should we do?
If you can’t reproduce it, then you don’t have a meaningful insight.
You might indeed discover a correlation, but you do need to validate it. If you use a completely fresh cut of data do you then find the same correlation?
If you do, then that’s an interesting pointer that something is indeed there that merits further research. If you don’t, then that would suggest that it was most probably a coincidence, something akin to finding random shapes in clouds.
We can be easily fooled.
If you are data mining using machine learning then one rather important safety net will be internal replication via an analysis of fresh data.
This is not a new problem. As it does in many other areas, technology simply acts as an amplifier for things that are already there. Our natural tendency is to find a correlation and then read into it an assumption of some sort of causal relationship. Taken to its extreme, this can and does lead some into conspiracy theory thinking or superstitious behaviours.
Researches have a new tool – machine learning – and so they have yet another way to simply fool themselves. Prior to machine learning we still managed to fool ourselves via cherry picking data or p-hacking. Machine learning introduces yet more potential for doing this. It can of course be a powerful tool. If we don’t take appropriate precautions and verify, we will end up being fooled.
Why is it like this?
Having an ability to rapidly identify patterns gave our species a distinct survival advantage and so pattern seeking has been naturally selected within us – we love patterns. Building better ways of doing this comes naturally to us.
The price we pay for our distinct pattern-seeking advantage are the false positives it yields. Now we build tools that greatly amplify our pattern seeking, hence we also amplify the false positives. We need to be very wary that a hit is not simply a false positive. We can do that by taking the time to verify that we have not simply been fooled with a bit of artificial pareidolia.
Be skeptical – doubt is your friend.
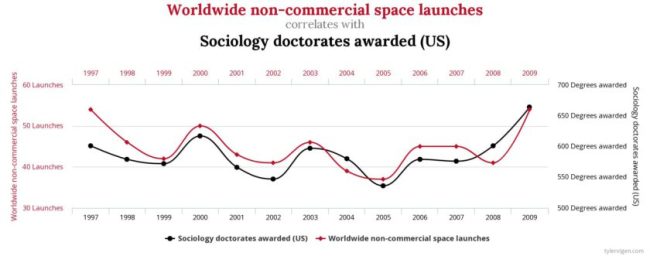
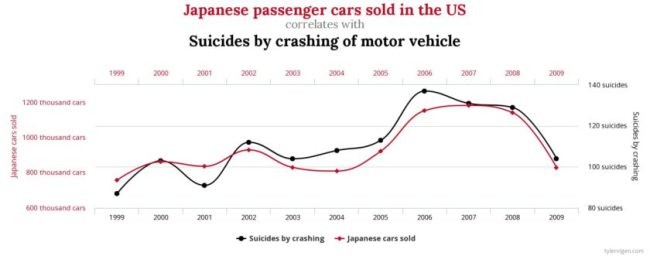
Spurious Correlations
Let’s have a bit of fun with this.
There exists a wonderful little site called Spurious Correlations that drives home the point that random meaningless correlations will pop up. If your dataset is large enough, then meaningless patterns can be found. These are just a coincidence, there is no causal relationship. In other words …
Correlation does not imply causation
… but why write that, why not instead show you a few examples taken from that site.
Enjoy.