
 At the recent Google I/O conference there was a demo of Google’s new Duplex AI Assistant. It was quite frankly amazing, so rather than describing it, you can instead see it yourself. Here is that demo …
At the recent Google I/O conference there was a demo of Google’s new Duplex AI Assistant. It was quite frankly amazing, so rather than describing it, you can instead see it yourself. Here is that demo …
“So umm Tuesday through Thursday we are open 11 to 2, and then reopen 4 to 9, and then Friday, Saturday, Sunday we… or Friday, Saturday we’re open 11 to 9 and then Sunday we’re open 1 to 9.”
When booking a restaurant, the lady answering misunderstands, and yet without any problem, it picks up and corrects her. It asks “I’d like to book a table for May 7th”. She replies, “For 7 people?“, and the AI responds, “No, for four people“.
What is clear is that those taking the calls from the AI have no idea that they are talking to a machine simulating a human. It is a very natural conversation laced with all the nuances of human speech and interaction.
Knowing that it is a machine you can probably pick up some very subtle hints that it is a machine, but if you had not been primed, then you would have not have known.
Doing this is very challenging
This is not simple stuff, the problem of mimicking human interaction is highly complex. The Google AI blog explains the scope of the problem like this …
When people talk to each other, they use more complex sentences than when talking to computers. They often correct themselves mid-sentence, are more verbose than necessary, or omit words and rely on context instead; they also express a wide range of intents, sometimes in the same sentence, e.g., “So umm Tuesday through Thursday we are open 11 to 2, and then reopen 4 to 9, and then Friday, Saturday, Sunday we… or Friday, Saturday we’re open 11 to 9 and then Sunday we’re open 1 to 9.”
In natural spontaneous speech people talk faster and less clearly than they do when they speak to a machine, so speech recognition is harder and we see higher word error rates. The problem is aggravated during phone calls, which often have loud background noises and sound quality issues.
In longer conversations, the same sentence can have very different meanings depending on context. For example, when booking reservations “Ok for 4” can mean the time of the reservation or the number of people. Often the relevant context might be several sentences back, a problem that gets compounded by the increased word error rate in phone calls.
 Deciding what to say is a function of both the task and the state of the conversation. In addition, there are some common practices in natural conversations — implicit protocols that include elaborations (“for next Friday” “for when?” “for Friday next week, the 18th.”), syncs (“can you hear me?”), interruptions (“the number is 212-” “sorry can you start over?”), and pauses (“can you hold? [pause] thank you!” different meaning for a pause of 1 second vs 2 minutes).
Deciding what to say is a function of both the task and the state of the conversation. In addition, there are some common practices in natural conversations — implicit protocols that include elaborations (“for next Friday” “for when?” “for Friday next week, the 18th.”), syncs (“can you hear me?”), interruptions (“the number is 212-” “sorry can you start over?”), and pauses (“can you hold? [pause] thank you!” different meaning for a pause of 1 second vs 2 minutes).What is truly impressive is that they have successfully met this challenge.
But how does it work?
Briefly like this …
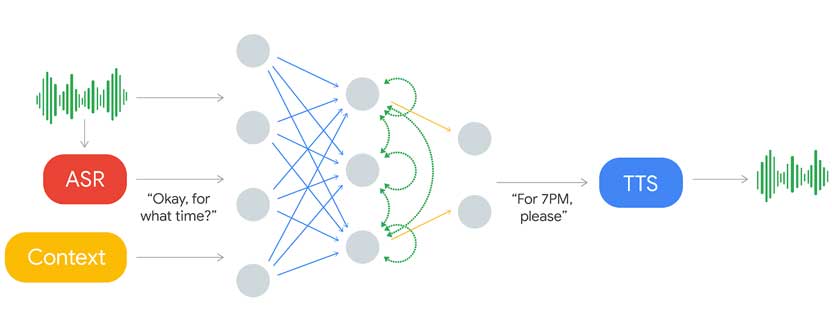
Human speech goes into the automatic speech recognition (ASR). This produces text that is analyzed with context data and other inputs to produce a response text that is read aloud through their text to speech (TTS) system.
That TTS also includes a synthesis TTS engine (using Tacotron and WaveNet) to control intonation depending on the circumstance.
They explain that TTS bit as follows …
The system also sounds more natural thanks to the incorporation of speech disfluencies (e.g. “hmm”s and “uh”s). These are added when combining widely differing sound units in the concatenative TTS or adding synthetic waits, which allows the system to signal in a natural way that it is still processing. (This is what people often do when they are gathering their thoughts.) In user studies, we found that conversations using these disfluencies sound more familiar and natural.
Also, it’s important for latency to match people’s expectations. For example, after people say something simple, e.g., “hello?”, they expect an instant response, and are more sensitive to latency. When we detect that low latency is required, we use faster, low-confidence models (e.g. speech recognition or endpointing). In extreme cases, we don’t even wait for our RNN, and instead use faster approximations (usually coupled with more hesitant responses, as a person would do if they didn’t fully understand their counterpart). This allows us to have less than 100ms of response latency in these situations. Interestingly, in some situations, we found it was actually helpful to introduce more latency to make the conversation feel more natural — for example, when replying to a really complex sentence.
Net effect of this is that it very successfully mimics human interaction.
Implications
It was promoted as an assistant that will simply phone up and make bookings for you. That however is not where this will go in the long term. You know that it will end up being incorporated into many different contexts.
One immediate and rather obvious observation is the thought of this technology being deployed to make robot calls. We have all received calls that are clearly machines. When invited to press 1 to speak to an operator so that you can buy a whizz-jig, (assuming you even listen that long), the vast majority will instead press “F-Off” by hanging up, then quickly add yet another number to a block list.
This however taps into our psychology. We think we are dealing with a human and so we spend a bit of time and effort going though the social norms of politely declining instead of a cold instant cutoff.
Is a machine that is perfectly mimicking a human and fooling you like this even ethical, because clearly you are being deceived?
Imagine this being deployed to send a misleading deceptive political or fraudulent message on a vast scale, and the voice used mimics somebody semi-famous such as a well-know political or business leader. You think they have personally called you, but it is just a machine. How comfortable do you feel about being tricked like that?
Regardless of how you might feel, pandoras box has been opened. Closing that lid is not an option.
Black Mirror Plot Twist.
This new Google Assistant dials 911 to make an emergency call for you and it is answered by Siri.
Further Reading
Google AI Blog – Google Duplex: An AI System for Accomplishing Real-World Tasks Over the Phone (Published May 8th 2018)